
Beim Programmieren stößt man früher oder später auf den Punkt, an dem im Code ein Fehler auftritt. Ohne Versionskontrolle wird dieser Zustand problematisch: Der aktuelle Stand des Programms enthält Fehler, und es gibt keine einfache Möglichkeit, zu einem früheren, fehlerfreien Zustand zurückzukehren. Aus diesem Grund legen Anfänger häufig manuell verschiedene Speicherstände an, bei denen jeder Speicherstand einen Meilenstein darstellt.
Obwohl diese Methode grundsätzlich nicht falsch ist, hat sie erhebliche Nachteile: Sie wird schnell unübersichtlich und kann für andere Entwickler verwirrend sein. Eine strukturierte und effektive Lösung bietet hier die Nutzung von Versionskontrollsystemen wie Git.
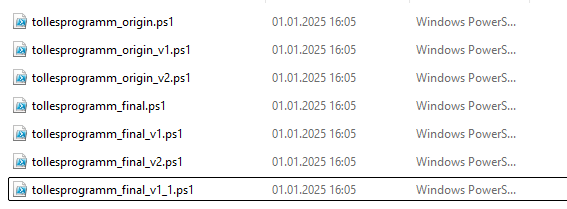
Abbildung 1: Verwirrende Speicherstände eines PowerShell-Programms zeigt verschiedene Speicherstände eines Projekts. Bereits anhand der Namensgebung ist es schwierig zu erkennen, welcher Speicherstand den aktuellen Stand des Projekts repräsentiert. Vermutlich gibt es Versionen mit fehlerhaftem Code sowie solche, in denen wichtige Features noch fehlen. Die Situation wird noch komplizierter, wenn man bedenkt, dass Projekte häufig nicht kontinuierlich entwickelt werden. Oft vergehen Monate, bis neues Wissen verfügbar ist oder ein Kunde detailliertere Anforderungen liefert. Durch diese zeitlichen Abstände können wesentliche Projektdetails in Vergessenheit geraten. Fragen wie „Warum gibt es so viele halbfertige Versionen?“ oder „Welche Version war die vollständigste?“ bleiben ungeklärt.
Um solche Probleme zu vermeiden, kommen Versionskontrollsysteme wie Git zum Einsatz. Diese Tools speichern die verschiedenen Zustände eines Programms in einer übersichtlichen Historie. Sie ermöglichen zudem die gleichzeitige Zusammenarbeit mehrerer Entwickler: Jeder kann lokal an einem bestimmten Stand arbeiten, und zu einem späteren Zeitpunkt werden die individuellen Änderungen auf einem Server zusammengeführt, um einen konsistenten Projektfortschritt zu gewährleisten. Sollte nachträglich ein Problem auftreten, kann das Programm jederzeit auf einen vorherigen Zustand zurückgesetzt werden.
Versionskontrollsysteme wie Git sind daher unverzichtbar für die kollaborative Softwareentwicklung.
GitHub und Git sind eng miteinander verbunden, aber sie sind nicht dasselbe. Hier ist eine kurze Beschreibung und Abgrenzung:
Was ist Git?
- Git ist ein verteiltes Versionskontrollsystem, das von Entwicklern verwendet wird, um den Quellcode eines Projekts zu verwalten.
- Es ermöglicht dir, Änderungen am Code nachzuverfolgen, ältere Versionen wiederherzustellen und kollaborativ an Projekten zu arbeiten.
- Git ist ein Tool, das lokal auf deinem Computer installiert wird und unabhängig von einer Online-Plattform funktioniert.
Was ist GitHub?
- GitHub ist eine webbasierte Plattform für die Zusammenarbeit an Projekten, die Git als Versionskontrollsystem verwendet.
- Es bietet eine Online-Umgebung, um Git-Repositories zu hosten, zu teilen und gemeinsam daran zu arbeiten.
- GitHub bietet zusätzliche Funktionen wie:
- Pull Requests für Code-Überprüfungen
- Issues für das Verwalten von Aufgaben
- Actions für automatisierte Workflows
- Sichtbarkeitseinstellungen (private oder öffentliche Repositories)
Installation von Git
Die Installation von Git ist denkbar einfach. Einfach „winget install –id Git.Git -e –source winget“ in das Powershell Terminal eingeben und bestätigen.
winget install --id Git.Git -e --source winget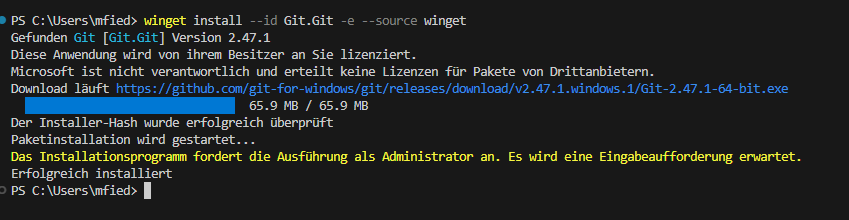
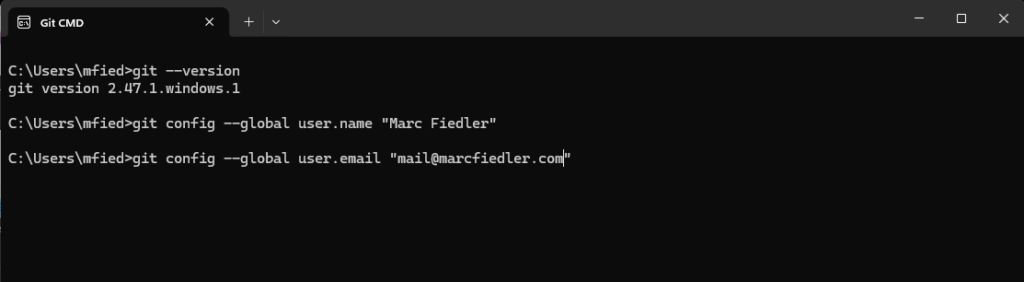
Als nächstes setzen wir unseren Benutzername und E-Mail.
Commit
Ein Commit erstellt einen Schnappschuss des aktuellen Programmstands und speichert ihn zusammen mit Metadaten sowie einem Verweis auf das vorherige Commit (falls vorhanden). Abschließend wird aus allen Daten ein eindeutiger Hashwert generiert, der den Commit unveränderlich macht und die Integrität der Historie gewährleistet.
Im Hintergrund arbeiten Zeiger wie der HEAD, der stets auf das aktuelle Commit zeigt, an dem gerade gearbeitet wird. Auf diese Weise entsteht eine manipulationssichere und nachvollziehbare Kette von Entwicklungsständen, die eine effiziente und transparente Versionskontrolle ermöglicht.
Der Aufbau in Git
Bevor wir in die Details eintauchen, betrachten wir zunächst den grundlegenden Aufbau von Git. Git arbeitet mit mehreren Bereichen, die unterschiedliche Funktionen erfüllen:
- Working Directory
Das Working Directory ist der Bereich, in dem sich die Dateien und Ordner unseres Projekts befinden. Diese Dateien müssen jedoch nicht zwangsläufig dem Git-System bekannt sein. Sie können bearbeitet werden, ohne automatisch versioniert zu sein. - Staging Area
Mithilfe des Befehlsgit addwerden Dateien aus dem Working Directory der Staging Area hinzugefügt. Diese dient als Zwischenablage, in der Änderungen vorbereitet werden, bevor sie endgültig ins Repository gelangen. - Git Repository
Durch den Befehlgit commitwerden die in der Staging Area erfassten Änderungen dem Git Repository hinzugefügt. Dort werden die Dateien versioniert und dauerhaft gespeichert, wodurch eine nachvollziehbare Historie entsteht.
Dieser Aufbau ermöglicht eine klare Trennung zwischen Bearbeitung, Vorbereitung und endgültiger Speicherung, was eine effiziente und strukturierte Versionskontrolle sicherstellt.
Ein Repository dient als zentrale Ablage für den Quellcode und seine Versionshistorie. Um ein neues Repository anzulegen, erstellen wir zunächst einen Ordner, in dem das Repository gespeichert werden soll. Anschließend initialisieren wir darin das Git-Repository mit dem Befehl:
bashCode kopieren git init myrepo
git init myrepoDieser Befehl erstellt den Ordner myrepo (falls er noch nicht existiert) und richtet dort die benötigten Git-Strukturen ein. Das Repository ist nun bereit, um Dateien zu verwalten und Versionskontrolle durchzuführen.
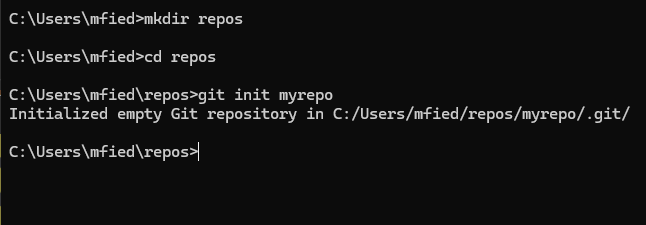
Nun befindet sich im Ordner myrepo der versteckte ordner .git.
Nun lernen wir unseren zweiten Befehl „Status“ diese Befehl gibt uns wichtige Informationen über das Repository.
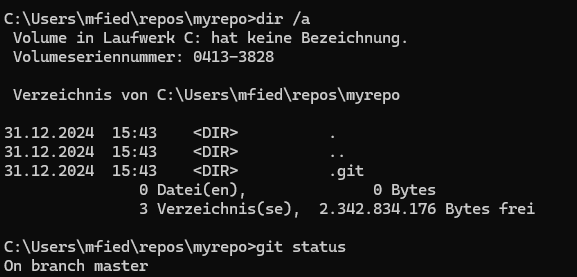
Als nächstes erstellen wir eine Übungsdatei im Repository. Dafür genügt es, eine einfache Textdatei (txt-Datei) anzulegen und beispielsweise den Text „Hallo Git“ darin zu speichern.

Wenn wir erneut den Befehl git status ausführen, wird die soeben erstellte Datei in roter Schrift angezeigt. Die rote Markierung weist darauf hin, dass die Datei noch nicht in die Git-Datenbank eingetragen ist und somit nicht von Git verfolgt wird (untracked).
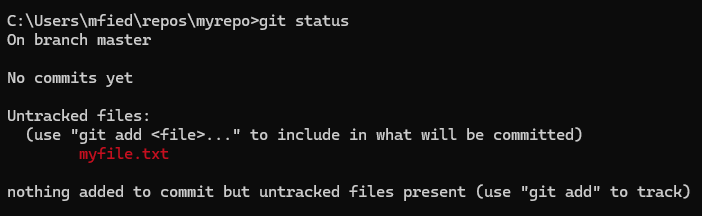
Damit Git die Datei myfile.txt verwalten kann, müssen wir sie mit dem Befehl git add myfile.txt zur Git-Datenbank hinzufügen.

Nun müsste bei einer erneuten Statusabfrage die myfile.txt in grüner Schrift erscheinen. Die grüne Schrift sagt uns, dass die Datei nun von Git verwaltet wird.
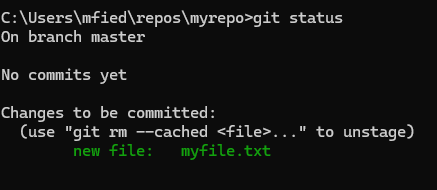
Nun möchten wir unseren ersten Schnappschuss, also unser erstes Commit, erstellen. Dazu geben wir in der Kommandozeile einfach git commit -m "unser erstes Commit" ein. Der Parameter -m ermöglicht es uns, eine Nachricht zum Commit hinzuzufügen. Diese Nachrichten sind nützlich, da sie den Zweck und die Änderungen des Commits dokumentieren und so für die Nachwelt nachvollziehbar machen.

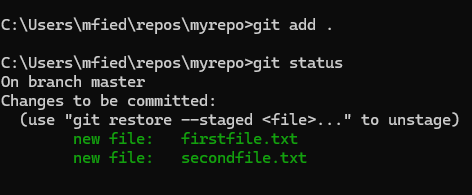
Nun erzeugen wir zwei weitere Dateien firstfile.txt und secondfile.txt

Mit dem Befehl „git add .“ können wir mehrere Dateien in die sogenannte „Staging Area“ übernehmen.
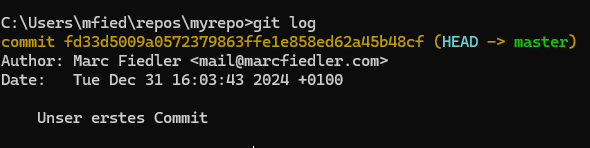
Ein weiterer wichtiger Git-Befehl ist git log, mit dem wir uns wichtige Informationen über unsere Commits, also die Versionsgeschichte des Repositories, anzeigen lassen können. Um eine kürzere und übersichtlichere Version der Logeinträge zu erhalten, können wir den Befehl git log --oneline verwenden.
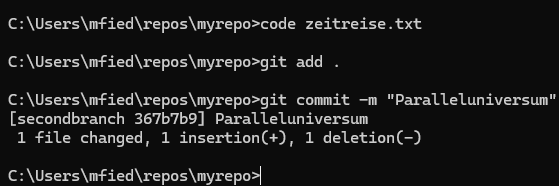
Wir erstellen eine Datei namens zeitreise.txt mit dem Befehl code zeitreise.txt und schreiben den Text „wir schreiben das Jahr 0“ hinein. Danach ändern wir die Datei und aktualisieren den Text auf „wir schreiben das Jahr 1000“. Anschließend führen wir wie gewohnt git add . aus, um die Änderungen zu stagen, und committen mit git commit -m "zweite Zeitreise". Dies wiederholen wir für die dritte Zeitreise ins Jahr 2000.
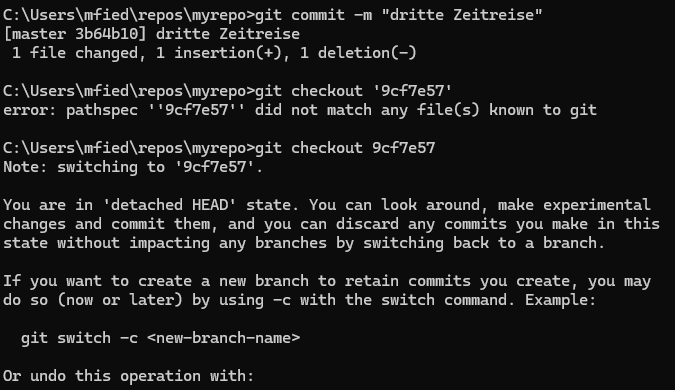
Zum Schluss verwenden wir den Befehl git checkout gefolgt von unserem spezifischen Hexadezimalwert, in diesem Fall 9cf7e57, um zu einem früheren Commit zurückzukehren.
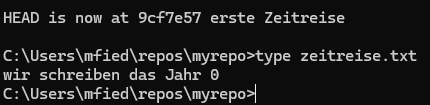
Mit dem Befehl type zeitreise.txt können wir den alten Text „wir schreiben das Jahr 0“ anzeigen lassen.
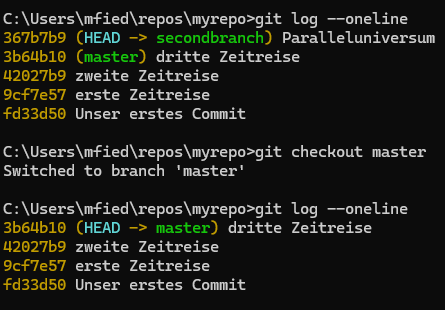
Um wieder zum Jahr 2000 zurückzukehren, müssen wir den Befehl git checkout master eingeben.

Änderungen rückgängig machen mit einem Revert-Commit:
Ein Revert-Commit erstellt ein drittes Commit, das die vorherigen Änderungen rückgängig macht. Der Befehl dazu lautet git revert <commit-hash>. Eine weitere Möglichkeit, Änderungen rückgängig zu machen, bietet der Befehl git reset --hard <commit-hash>.
Verzweigungen nutzen (Branch):
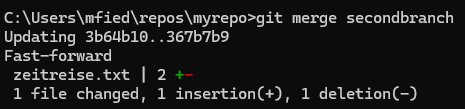
Um mehrere Versionen unseres Programms zu erstellen, können sogenannte „Branches“ (Zweige) angelegt werden. Ein Branch wird mit dem Befehl git branch <Branchname> erzeugt, und mit dem Befehl git checkout <Branchname> wird zwischen den Branches gewechselt. Um zu sehen, auf welchem Branch wir uns gerade befinden, gibt es den sogenannten „Head“-Zeiger. Der Head zeigt immer auf den aktiven Branch, auf dem wir gerade arbeiten. Im Folgenden werden wir mithilfe von Branches ein Paralleluniversum des Jahres 1000 erzeugen.

Fazit und Ausblick
Wir haben nun die Grundlagen von Git kennengelernt und einen soliden Überblick über die lokalen Versionskontrollen, das Verwalten von Änderungen sowie das Arbeiten mit Branches gewonnen. Mit Git sind wir in der Lage, eine strukturierte und nachvollziehbare Historie unserer Programmversionen zu führen. Doch Git ist nicht nur ein Tool für die lokale Versionierung – auch die Zusammenarbeit zwischen mehreren Entwicklern erfordert zusätzliche Funktionen, die Git in Verbindung mit Plattformen wie GitHub bietet.
Im nächsten Teil werden wir uns intensiv mit GitHub beschäftigen. Wir werden lernen, wie man ein Git-Repository auf einem Server hostet, mit Remote-Repositories arbeitet und wie wir die Zusammenarbeit mit anderen Entwicklern optimieren können. Außerdem werden wir die Vorteile von Pull-Requests, Code-Reviews und die Verwaltung von Berechtigungen auf GitHub untersuchen. Freuen Sie sich auf eine vertiefte Auseinandersetzung mit der serverseitigen Verwendung von Git und den effizienten Arbeitsabläufen in Teams!
No responses yet